3. How it works (RAG)
The "Retrieval-Augmented Generation" (RAG) version (available on the ollama-pinecone branch) mimicks training an LLM on an internal knowledgebase.
It will produce custom destination advice for places the system has explicitly been trained on (the files in the destinations folder).
Namely, Bali and Sydney. For other locations, the model will provide an answer based on its own knowledge.
It is based on Ollama and uses PineCone as a Vector database. The RAG pipeline is built using LangChain.
The RAG version of the demo mimicks training an LLM on an internal knowledgebase.
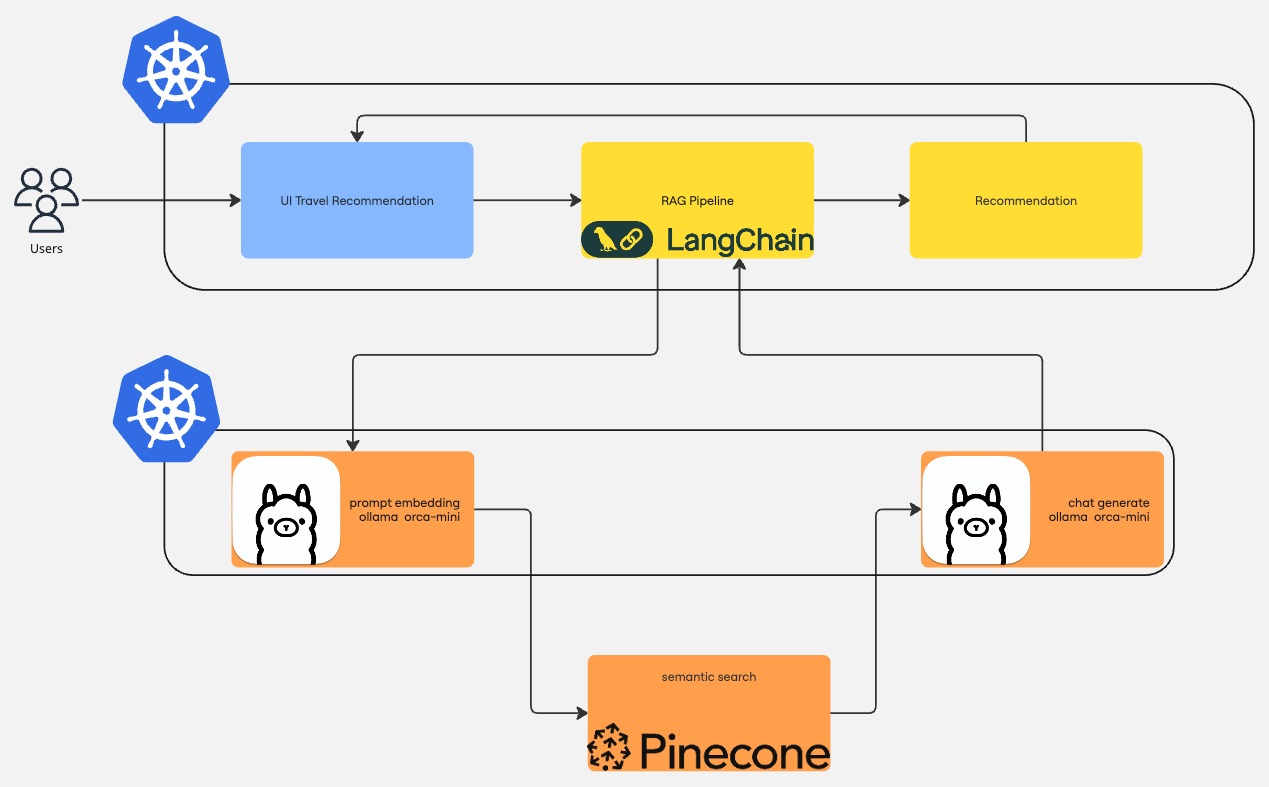
When the application starts, files inside the destinations folder are read, processed, and stored in PineCone for later lookup. Afterwards, each request goes through the LangChain RAG pipeline, which performs the following steps:
- It contacts Ollama to produce an embedding of the user input
- With the embedding, reach out to PineCone to find documents relevant to the user input
- Use the documents to perform prompt engineering and send it to Ollama to produce the travel recommendation
- Process the answer received